i仕様書の機能
やっと、今回はi仕様書です。ここも、大事な事がたくさんあります。
AS/400 RPG/400 使用者の手引き 資料番号 SC88-5203-00
| 2.1.5 入力仕様書 入力仕様書には、プログラムで使用する入力ファイル内のレコード、フィールド、データ構造、および名前付き固定情報を記述します。入力仕様書に含まれる情報としては、以下のものがあります。
- ファイルの名前
- レコード・タイプの順序
-
レコード識別標識、制御レベル標識、フィールドとレコードの関連標識、またはフィールド標識を使用するかどうか
-
データ構造、先読みフィールド、レコード識別コード、または突合せフィールドを使用するかどうか
- 各フィールドのタイプ(英数字か数字か。パック10進数かゾーン10進数または2進数形式か)
- レコード内の各フィールドの位置
- レコード内の各フィールドの名前
- 名前付き固定情報
|
レコードの定義
内部記述(プログラム記述ファイル)
レコード様式の定義
何桁目から何桁目で、数字か文字か、そしてその部分の名前(フィールド名)の定義。F仕様書で外部記述指定をしたら不要です。内部記述の指定では、レコード様式は出てきません。よって、内部記述では、レコード様式を指定するC仕様書の命令は一切利用できません。また、下図のFILEには、そのままファイル名が入ります。
IFILE AA 01
I 1 1 DTAID
I 2 7 CHGDT
I 8 120DTASEQ
I 13 130SLDFLG |
外部記述
通常は、I仕様書は定義しなくてもすみます。
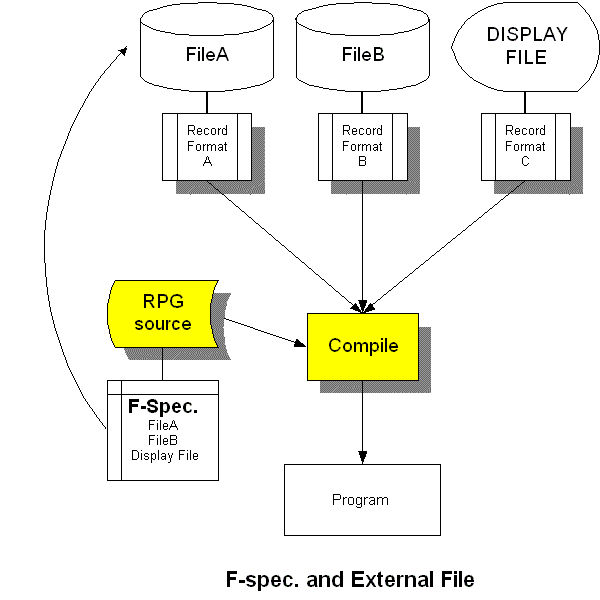
これは、前に説明しましたね。少し具体的に話しましょう。
レコード様式とは、いくつかのフィールドの集まりでしたね。これをDDSで定義するファイルから取り出すのです。
ファイル名はFILEAとして作成するとします。 A*------------------------------------*
A R FILEAR ←レコード様式名
A*------------------------------------*
A Z1FLDA 5A COLHDG('FLDA')
A Z1FLDB 3S 0 COLHDG('FLDB')
A Z1FLDC 8A COLHDG('FLDC') |
CRTPFで上記のDDSから、物理ファイルFILEAを作成すると、
| レコード様式 FILEAR |
| 1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
| Z1FLDA |
Z1FLDB |
Z1FLDC |
というレコード様式が出来ます。これをもし、内部記述で書くとすれば、下の様になります。
IFILEA AA 01
I 1 5 Z1FLDA
I 6 80Z1FLDB
I 9 16 Z1FLDC |
一つの構成、Z1FLDA+Z1FLDB+Z1FLDCのレコードの表記方法が、
- DDSでは、各フィールドの桁数の定義、
- RPGでは、各フィールドの開始位置と終了位置
となります
(桁数) = (終了位置 - 開始位置 + 1)ですので、DDSも内部記述も、結果的に同じ事を指定していることは、おわかりですよね。外部記述にすると、上記のレコードの定義を、RPGはコンパイルの時に取り込んで、勝手に内部記述と同じ事をしてくれます。コンパイルリストを注意深く見れば、分かります。これが、外部記述の機能です。つまり、F仕様書で、ファイル名を外部記述ファイルとして、定義すると、コンパイラはそのファイルの記述を検索して、そのレコード様式を取り出すことに注意してください。外部から何か記述を取り出すときは、コンパイラに対して、オブジェクト名(この場合、ファイル名)を指定するのです。※レコード様式そのものは、独立したオブジェクトではあません。
レコード様式の識別子の定義(複合論理ファイルを使用する場合)
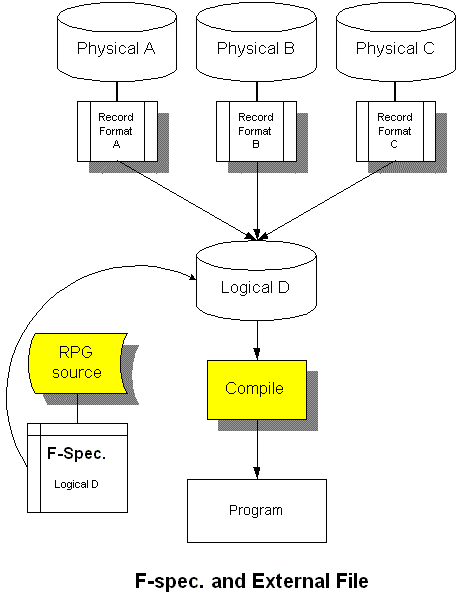
複合論理ファイルは、いくつかの物理ファイルを、一本の論理ファイルとしてまとめるものです。つまり、ファイルは一本ですが、レコード様式は複数あることになります。C仕様書で、今読み込んだのがどのレコード様式なのか識別しなくては、プログラムが出来ないはずで、その場合、「レコード標識」を指定します。このほかにも、サイクル処理の場合、指定する場合があります。
IRecordA 01
IRecordB 02
IRecordC 03 |
この定義で行くと、レコードRecordAを読み込むと、標識01が(勝手に)ONとなり、レコードRecordBを読み込むと、標識02がONとなり、レコードRecordCを読み込むと、標識03がONとなります。この標識で、今読み込んだのが、もし、RecordAならば、ああして、RecordBならば、こうして、RecordCならば、...とC仕様書で記述できます。
フィールドの名前変更
何らかの理由で、外部記述上のフィールド名の名前を変えたい場合に使います。
「何らかの理由」とは、
- フィールド名が6桁を越える場合。(ILEでは6桁以上も、可能。QRYの出力ファイルでよくあるパターン。)
- 画面のフィールドを配列にしたい場合。画面フィールド名をARY,1に、などと使う。
- 2つのファイルが同じフィールド名を持つ場合、このレコード様式ではAAAAという名前、このレコード様式ではAAAFLDという様に、名前を変更する。
というものです。
C仕様書では、赤い文字のフィールドが使われます。 IRecord
I AAAA AAAFLD
I BBBB BBBFLD
I CCCC CCCFLD
I DDDD DDDFLD
I EEEE EEEFLD
下は、配列の場合(AAAAからEEEEは、すべて同じ属性のフィールドでなければならない。勿論、E仕様書で、ARYは定義すること。)
IRecord
I AAAA ARY,1
I BBBB ARY,2
I CCCC ARY,3
I DDDD ARY,4
I EEEE ARY,5 |
RPGサイクルのレベル標識の指定
IRecord
I KEY01 L1
I KEY02 L2
I KEY03 L3
I KEY04 L4
I KEY05 L5 |
データ構造(Data Structure)の定義
データ構造の定義は、必ず、上記のレコード様式の定義の「後」にしないと、コンパイルエラーとなります。理由は不明ですが、同じI仕様書の中でも、順番として、
- 「レコード定義」
- 「データ構造定義」
の順番でなくては、なりません。レコード定義と、データ構造の違いは、DSという言葉(下図の赤い字)です。
I DS
I 1 140DSDTTM
I 1 60DSQTIM
I 7 140DSQDAT |
この「DS」の位置は、上記「レコード様式の識別子の定義」のレコード識別子の位置と同じです。
データ構造とはなにか
まずはマニュアルを見てください。
AS/400 RPG/400 使用者の手引き 資料番号 SC88-5203-00
9.2 データ構造
RPG/400
プログラムでは記憶域内のある区域およびその区域内でのサブフィールドと呼ばれるフィールドのレイアウトを定義することができます。記憶域内のこの区域は、データ構造と呼ばれています。データ構造を使用して次のことを行うことができます。
- 異なるデータ形式を使用して同じ内部域を複数回定義する。
- フィールドに対して操作を行い、その内容を変更する。
- MOVE または MOVEL
命令コードを使用しないでフィールドをサブフィールドに分割する。
- データ構造およびそのサブフィールドをレコードを定義した時と同様に定義する。
- データのセットを複数回繰返して定義する。
- 連続していないデータを隣接する内部記憶域の位置にグループ化する。
さらに,ぞれぞれ特定の目的をもった3つの特殊なデータ構造があります。
- データ域データ構造(データ構造ステートメントの 18 桁目のUで識別)
- ファイル情報データ構造(ファイル仕様書の継続記入行のキーワード
INFDSで参照)
- プログラム状況データ構造(データ構造ステートメントの 18
桁目のS で識別)
データ構造はプログラム記述とすることも、外部記述とすることもできます。 |
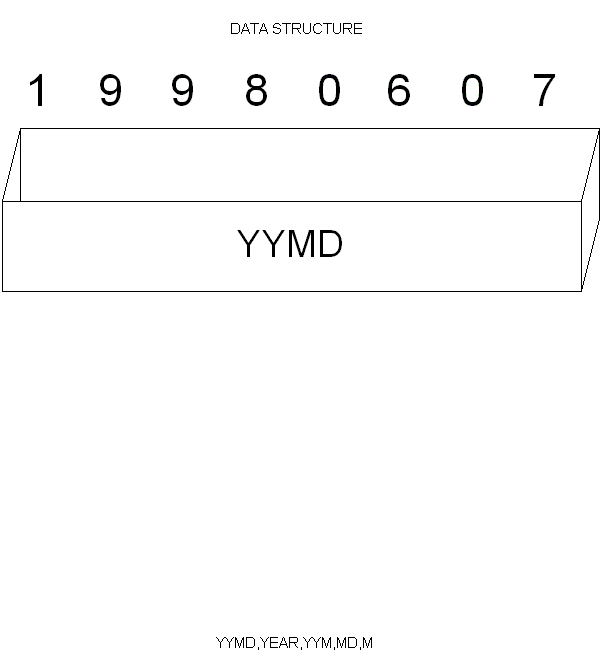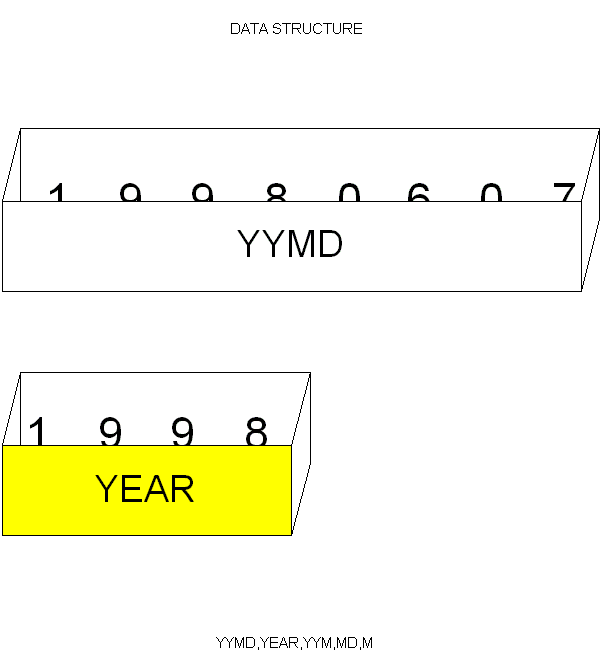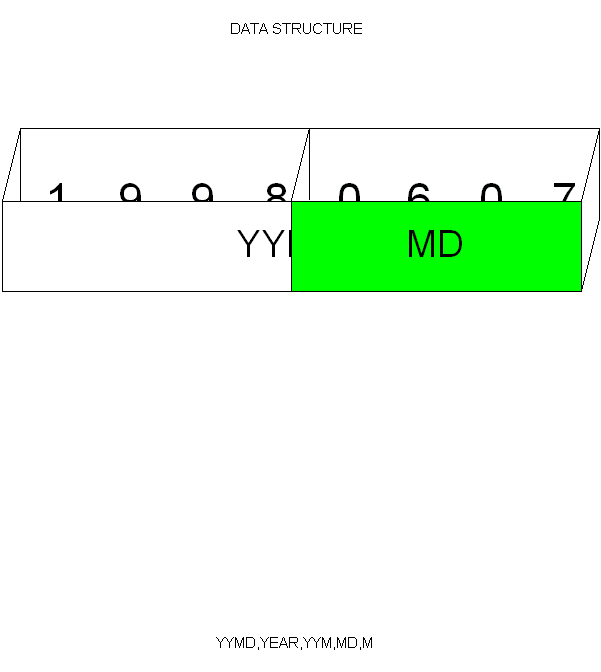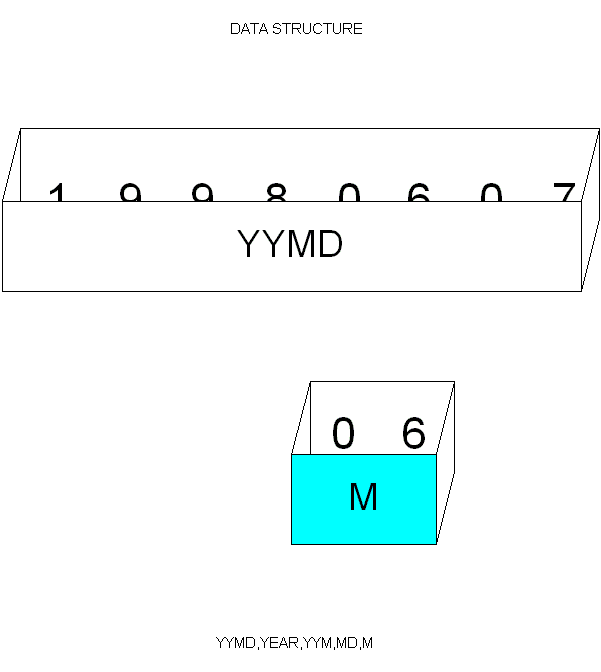
データ構造の概念図
下図はデータ構造の概念を理解するものです。一つのデータ構造は、いくつかのサブフィールドから構成されます。
I DS
I 1 80YYMD
I 1 40YEAR
I 1 60YYM
I 5 80MD
I 5 60M I DS
I 1 80YYMDA
I 1 40YEARA
I 1 60YYMA
I 5 80MDA
I 5 60MA |
YYMDは、8桁の数字フィールドで、その内部が分割され、各々名前を持ちます。
このデータ構造は、「あるデータが、いくつか別のデータから構成されている、という静的な(動的ではない)データの定義」です。コボルで言えば、再定義(REDEFIN)のことと思えばいいでしょう。上図の水色の部分で、一つのまとまったデータ構造になります。また、同じ図の、データ構造(下)で、もし、YYMDAがYYMDと、上のデータ構造と同じ場合は、「既に使われたサブフィールド」として、コンパイルエラーになります。サブフィールド名は重複してはいけません。
| 1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
| YYMD |
| YEAR |
|
| YYM |
|
| |
MD |
| |
M |
|
なぜデータ構造を使うのか
このように、定義した、YYMDにデータをセットすると、自動的に、YYM,MD,Mからデータを取り出せます。逆に、YEARとMDに数字をセットすれば、YYMDを作成する事も可能です。
このように、データ構造は、「データの分解」と「データの組立」によく利用します。例では、数字ですが、このほかに商品コードの組立とか、郵便番号を分解して、ハイフンをつけたり、電話番号を市外局番から組み立てて、一つのフィールドにしてみたり、とにかく、データを分解したり、組み立てたり、こんな場合に頻繁に使う機能です。
外部データ構造とはなにか。
データ構造も、外部のファイルからそのレイアウトを取ることが出来ます。上の、「内部記述のi仕様書」と「DSの記述」がそっくりな事に気づいた方もいらっしゃるでしょう。そうです、ファイルのレイアウトをそのまま、DSとしてしまうことが出来ます。これが、外部DSです。
Idsname DS
I 1 80YYMD
I 1 40YEAR
I 5 80MD
Idsname E DSfile |
上が通常のデータ構造、下が外部データ構造です。先ほどは書きませんでしたが、データ構造に名前を付けることが可能です。dsnameがそれです。内部で定義するデータ構造の場合は、DS名は省略可能ですが、外部DSの場合は、DS名は必須です。fileはファイル名です。レコード様式名ではありません。外部データ構造は、外部記述のファイルと、同様に、その定義を、コンパイル時に取り込んでくれます。E
DSと覚えてください。尚、EIDS(Eの後に、初期化のIが入る)では、プログラムの呼び出し直後、一回のみ、初期化してくれます。
初期設定
データ構造は様々な機能が付加されていますが、特に覚えて欲しいのは、初期設定済みにする方法です。
この初期化は、プログラム呼び出し直後の、最初に一回のみ、行われます。プログラムで書き換えて、また元に戻したいときは、RESET命令をC仕様書で使います。(昔(随分前)はこの命令は無かったです。)
I iDS
I 1 120DSDTTM
I 1 60DSQTIM
I 7 120DSQDAT |
上図は、データ構造をまとめて初期化します。数字は0、文字はブランクです。
I DS
I i 1 120DSDTTM
I i 1 60DSQTIM
I i 981010 7 120DSQDAT |
上図は、サブフィールドを個別に初期化しています。数字は0、文字はブランクです。まとめて初期化する場合は、出来なかった「固定情報」のセットも可能です。例では、981010をDSQDATにセットしています。つまり、DSDTTMは000000981010になります。
さらにいろいろある、データ構造
- データエリアと連携したデータ構造
- オカレンス(複数回指定)データ構造
- プログラム状況データ構造
- ファイル情報データ構造
ここでは、以上は割愛します。入門編では不要と考えました。本編で説明したところは、いつも使う重要な部分です。まずは、ここから、習得してください。ここが分からなければ、別のデータ構造の内容を読んでも、無意味です。
名前付き固定情報の定義
RPGでは、固定情報を書き込めるのは、C仕様書の演算項目1または2ですが、シングルコーテーションの括る必要が有るため、実質、8文字までしか定義できません。そして、この名前付き固定情報は、それ以上の長さを指定できます。この名前付き固定情報が無かった頃は、配列のコンパイル時配列を利用していました。勿論、この配列を使っても最大80文字まで可能です。この名前付き固定情報の記入位置は、I仕様書の中なら、どこに記入しても、コンパイルは通ります。
I X'31' C F1
I X'32' C F2
I '入力桁がオーバー- C OVRFLW
I 'フローしました'
1行に収まらないときは、-をつけて次の行に続けることが出来る。CはCONSTANTのこと。 |
上図では、F1という特殊な固定情報用のフィールドが、16進数31(16進数の場合は、16進数(またはヘキサ)サンイチと読む。サンジュウイチは10進数の読み方)という固定情報を持つように定義されています。ところで、ここで定義されたフィールドは、普通のフィールドの様に、変数とはなりません。データを最初から持つ、変更不可能なフィールドです。ですので、F1とかF2とかOVRFLWなどの様に、名前つき固定情報として定義してしまうと、そのプログラムでは、それらは普通のワークフィールドとしては、使えなくなります。注意してください。
尚、桁位置を暗記する必要はありません。SEU(ソースエディタ)の機能は、かなり高度で、プロンプトを呼び出して入力出来ます。それに、慣れてくれば、桁位置は、自然に身に付きます。この辺は、あまり神経質にならないでください。(桁位置はどうでもいい、ということではないですよ)。それよりも、どのようなことが出来るのかという、機能とか仕様を覚えてください。
では今日はここまで。次回は、C仕様書を、スキップして、O仕様書の解説をします。その後に、C仕様書にすすみます。
起立、礼、着席
1998/6/14 | 