|
|
|
Wiki | ||
|
updated on 2004.06.23 |
||||
17.9.RPGの基本(アイを語る前に) | |||||||||
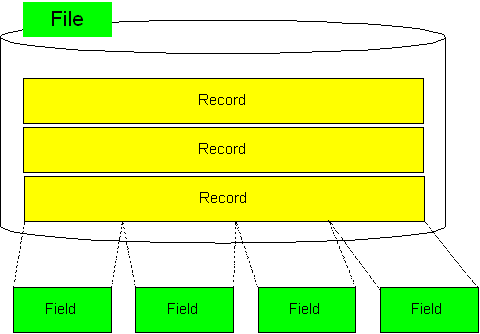
Where do I begin ? (「ある愛の詩」より)今日は、アイのお話です。Inputのi仕様書です。「HFELICO」のIですね。L仕様書はもう使わないと思いますのでスキップします。L仕様書は、印刷装置ファイルのオーバーフローとかの定義で、System36では使うのですが、System38,AS/400では、オブジェクトとしてのプリンターファイルの定義の中に、もっと詳しく定義できるので、L仕様書は死んだも同然です。(PRTFの関連コマンドは、CRTPRTF,CHGPRTF,OVRPRTF,DSPFD,DLTF(注意:削除の場合)です。) i仕様書はプログラムにとっては、レコードの入り口です。この入り口を入らないと、プログラムは、データを取り込めません。また、データは必ず、フィールドという箱に収まって、取り込まれます。 さて、ここでは、まずi仕様書を理解するための前提知識を説明します。でないと、いくら定義の方法を学んでも、何の役にも立ちません。 レコードから、データを取り出す概念※レコードとは、データの集まりです。ファイルを直接構成するものです。ファイル単位に、レコードの長さが決まっている「固定長レコード」が原則です。ファイル内では、すべて同じレコードの長さです。当然、これは、ファイルが違えば、そのレコードの長さも異なります。(偶然、2つのファイルのレコードが同じ長さ、ということも勿論ありますよ)。いづれ、ファイルとは、レコードとは、と言うことは、必ず分かってきます。ここではさらっと流して、 「フィールド」の集まりが「レコード」、「レコード」の集まりが「ファイル」、と単純に覚えてください。 プログラムがレコードから欲しいもの
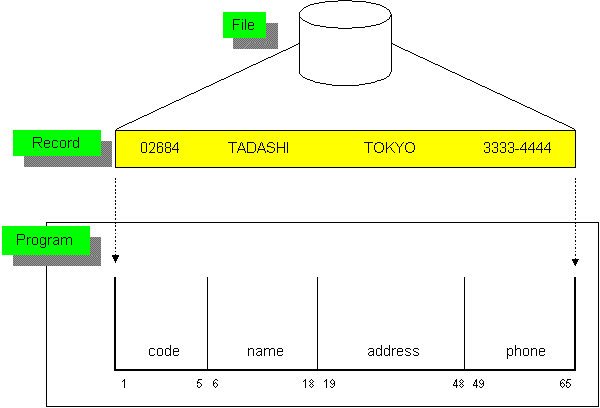
このレコード入力の目的は、簡単に言えば、レコードを構成するフィールドの中のデータを取り出すことです。この図で言えば、「File」の中の「Record」を読み込み(読み込み命令はC仕様書で行います)、そのレコードがOSにより、プログラムに与えられた結果、「Field」に分解されて、「Data」を取り出すことになります。この「Data」を、プログラムは使いたいのです。 さて、プログラマーのあなたがすべきことは、このフィールドの構成を、プログラムの中で定義して、そのレコードをくれ、とOSに命令するだけです。それだけで、フィールドの中に、データは入ってきます。でも、それだけでは、理屈が分からないでしょうから、もっと詳しく説明します。 (※図がすべて英語なのは、Visoでgifに変換すると、NTでは、漢字が文字化けしてしまうためです。あしからず。) 入力レコードとフィールドへの分解では、レコードがプログラムに如何に取り込まれ、その結果、どのようにフィールドデータを取り出すのかの説明をします。下の図は、ファイルから取り出されたレコード(フィールドデータの集まり)が、プログラムの中で、如何に分解されて、意味のあるフィールドのデータとなるかを表したものです。また、レコード中が、「02684TADASHI TOKYO 3333-44444」という、なんだか(勘で分かりそうですが)、意味不明の一連の文字データであることに注意してください。
C仕様書のレコード読み込み命令(CHAINとかREADなど)に基づき、OSは、ファイルから、取り出されたレコードデータを、プログラムの中の「入力域※」にセットします。
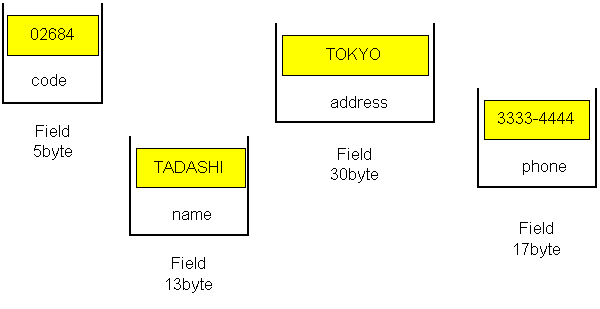
この入力域は、内部的に分割されていて、たとえば1バイト目から5バイト目はcodeという名前がつけられています。この名前が、フィールド名です。つまり、入力域を、フィールド群に分割しています。図で例として挙げたフィールド名は、code,name,address,phoneです。その下の小さく見える数字は、桁位置を示します。codeの下に 1 5と出ていますね。これは1から5桁までをcodeと名付けたのです。よって、このcodeの長さは5バイトです。同様に、nameは13バイト、addressは30バイト、phoneは17バイトです。 それから、この図からも分かるように、フィールドの構成を見ると、「フィールド自身の定義」と、「複数のフィールドの順番」も定義されていますね。たとえば、codeの隣は。、nameで、その隣はaddressで。こうのように、フィールドの並び順も大事なことです。これは、桁をどこから、どこまで、何々フィールドと、次々に指定しているからです。 ここでの、ポイントは、
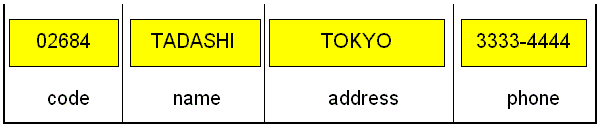
です。 ※また、これとは逆に「出力域(出力バッファレイアウト)」も存在します。つまり、「入力」とは、逆の働きをするものです。プログラムから、レコードを作成して、ファイルに書き込むときに、この出力域を定義します。※よって、入力域と出力域は、全く別物です。独立して、存在しています。ここでは、入力がメインの話題ですので、出力域の図は出していません。 データを分解この図では、入力域にレコードのデータが、各フィールドに収まったところを表現しています。まるで、包丁で黄色い羊羹を切ったようですね。つまり、長さがまちまちの黄色の羊羹が出来るわけです。
プログラムが欲しかったものが出てきたこれで、フィールドに、無意味だったデータが、きれいに分解されて、意味のあるものとして取り込まれました。codeは02684で、nameはTADASHIで、addressはTOKYOで、phoneは3333-4444です。「フィールド」とは、プログラムの中でデータを保持する、最小の変数です。この入力域を通過すれば、その後のプログラムの処理では、codeの中に02684というデータが入っていて、C仕様書、O仕様書など、このi仕様書に続く処理の中で、そのフィールドの中のデータを扱えるのです。
この後、プログラムはこの、codeやnameといった、データの入ったフィールドを自由に扱えます。但し、注意してほしいのは、この例では、簡潔にするため、これしか出していないのですが、フィールドの属性(フィールドを形づける、様々な要素)はほかにもあります。図にあるものも含めて列挙しますと、
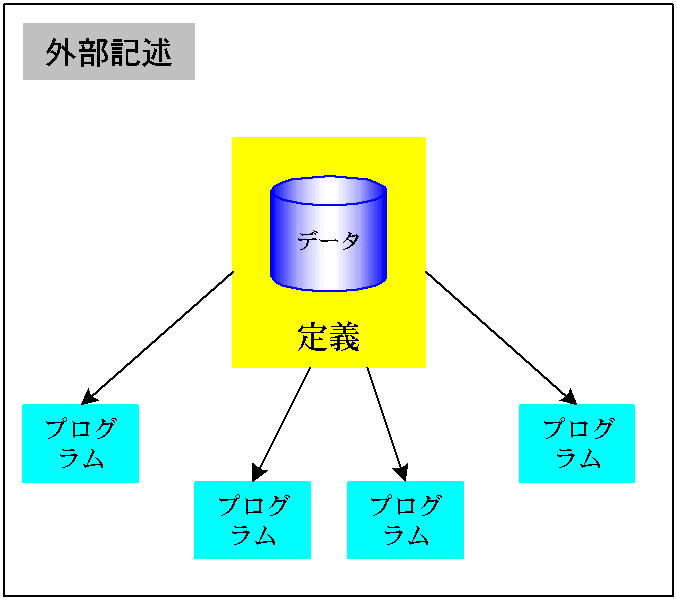
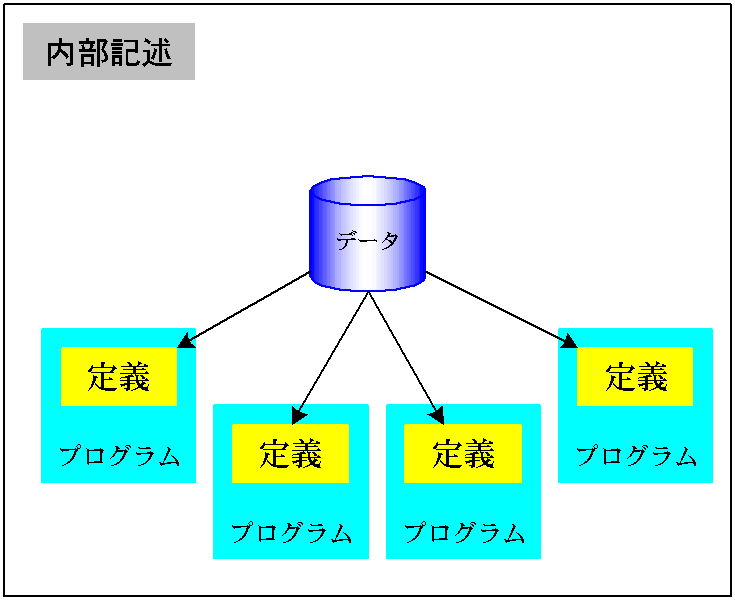
が重要な要素です。平たく言えば、「どっからどこまで、どんなフィールドか」、となります。 ここで、説明していなかったのは、データタイプです。これは、「文字」とか「数字」のことです。数字はさらに、整数部分の桁数、小数点以下の桁数、さらに、記録上のデータの保管形式として、ゾーン十進数、パック十進数、2進数形式があります。これらの、形式については、後述しますが、マニュアル「RPG/400 使用者の手引き データ・フィールド形式およびデータ構造」に詳しく出ています。 以前も伝えましたが、ここでは、外部記述に的を絞ります。内部記述は、いずれ説明する機会があると思います。念のため、各々の違いを説明します。 外部記述これはプログラムの外部にファイル(レコード:入力や出力のレコードレイアウト)の記述がある、と言うことです。ファイルからのデータを取り込む入力エリアの定義(上図参照)が、プログラムの作成以前(コンパイル以前)に存在しているのです。コンパイラは、この内容を勝手に取り込んでくれますので、入力域の定義は、プログラムの内部ではなく、プログラムの「外」から取り込まれます。だから、外部記述と言います。 内部記述これは、プログラム内部でファイルの入力域を定義します。読み込まれたデータを、フィールドに分解します。でないと、この後でそのフィールドが使えません。そこで、何桁目から何桁目を、これこれと命名する、と言う感じで、フィールドを定義していきます。(面倒ですね)。 さて、ここでは、「外部記述」だけを取り扱います。
レコード様式これは、RPGではなく、DB2/400の概念です。でも、これを知らないと、先に進めません。そこで、簡単に説明をします。 ファイルの定義は、主に2つの部分から構成されています。「レコード様式」と、「アクセスパス」です。アクセスパスは別の機会に説明します。
早い話、レコード様式は入力(及び出力)域の定義のことです。(そのほかの、属性も持っていますが、主たる内容は、レコードのレイアウトの定義です)。これは、入力だけでなく、出力のレコードのレイアウトを含みます。通常のファイルは、入力レイアウト=出力レイアウトです。ですので、どちらでもいいのですが、論理ファイルの中で、入力のみのフィールドがありますので、このようなファイルは入力レイアウト≠出力レイアウトになります。 さて、ここで注意して欲しいのは、レコード様式は、きわめて完成された、レコードを定義する概念である事です。さらに、OSの中枢深くに関わるものです。 まず、ファイルの記述ありきこのレコード様式は、DDS(データ記述仕様;Data Description Specification)で記述され、名前を持ちます。また、プログラム外部記述が参照するのは、このレコード様式です。普通に、ファイル用のDDSを作成して、CRTPFをすると、ファイルが作成されます。そして、このレコード様式は、必ずこの中に含まれます。例外はありません。プログラム外部記述の「外部記述」とは、「プログラムの外部のある、このファイルの中の、レコード様式(とアクセスパス)の記述」を意味します。RPGのF仕様書で、ファイルを、この外部記述の指定をして、CRTRPGPGMをする(コンパイル)をすると、このファイル記述のレコード様式から、入力域のレイアウトを取り出し、プログラムを作成します。したがって、見方を変えると、DDSでCRTPFをした時点で、レコードのレイアウトはオブジェクトを構成する一部として、すでに存在するわけです。(レコード様式そのものはオブジェクトでは無く、オブジェクト*FILEの中身の一部(もしくは構成物)として存在します。) プログラム外部記述では、当然、入力域や出力域は、プログラムの作成前に出来ている事が前提です。もし無ければ、コンパイルエラーです。よって、i仕様書で定義すべきだった、入力域部分の大半は、実は、ファイルの中のレコード様式にあるのです。内部記述の場合は、プログラム単位に入力レコードのレイアウトを、1 5 code, 6 18 name、と地道に入力しなくてはなりませんが、外部記述の場合は、その手間が省けます。それどころか、一つの定義を、たくさんのプログラムが、共有して、定義を取り出しますので、まちまちの定義をしなくなり、合理的です。 入力域の定義は、どんなプログラム言語でも出てくる概念です。ただし、この「レコード様式」は、AS/400固有の概念です。もう、おわかりと思いますが、外部記述でレコードレイアウトを取り出しても、内部記述でレコードを設計に従って記述しても、結果は同じです。このレコード様式は、プログラムだけでなく、DFUやQRYといったツールでも利用される、中核となるものです。心して、学んでください。 またこのファイルとレコード様式、アクセスパス、データメンバーに関しては、別の機会に説明します。 次回は、i仕様書の定義についての話です。 それでは、今日はこの辺で、 起立、礼、着席 |
|
You are at K's tips-n-kicks of AS/400
|
| SEO | [PR] 爆速!無料ブログ 無料ホームページ開設 無料ライブ放送 | ||