CCSIDの構成要素
文字セット or 図形文字セット (Character Set:CS)
文字の集まりは文字セットと呼ばれ、場合によっては図形文字セットと呼ばれます。これらは、ビットパターンイメージにつけれられる、「図形文字セット・グローバル識別コード (GCSGID)」を集めたものです。
コード・ページ (Code Page:CP)
コード点に割り当てられた文字の集まりです
コード点が特定のコード・ページ内の文字に割り当てられるときに使用される規則を指定します。たとえば、EBCDICそのものも、ESになります。漢字では、0e0fによる漢字表現もESです。コード化の手段、様式、方法、...そんな意味です。
- CHRID = CS + CP
-
CCSID = CHRID + ES = CS + CP + ES
よく目にするSBCSのCCSID
※すべてのCCSIDの一覧表は、14.29.コード化文字セット識別コード (CCSID)を見てください。
| CCSID |
CHRID |
コード化スキーマ(ES) |
説明 |
| 文字セット識別コード(CS) |
コードページ(CP) |
| 37 |
697 |
37 |
1100 |
アメリカ、カナダ、オランダ、ポルトガル、ブラジル、ニュージーランド、オーストラリア |
| 290 |
1172 |
290 |
1100 |
日本語カタカナ(拡張範囲) |
| 897 |
1122 |
897 |
2100 |
日本語 PC データ(非拡張) |
| 1027 |
1172 |
1027 |
1100 |
日本英語(拡張範囲) |
よく目にする混合CCSID
| CCSID |
SBCS
/DBCS |
CHRID |
コード化スキーマ(ES) |
説明 |
| 文字セット識別コード(CS) |
コードページ(CP) |
| 930 |
SBCS |
1172 |
290
(拡張、非拡張) |
1301 |
日本語カタカナ(拡張範囲)4370 UDC(ユーザー定義文字) |
| DBCS |
1001 |
300 |
| 932 |
SBCS |
1122 |
897 |
2300 |
日本語 PC データ - 混合 |
| DBCS |
370 |
301 |
| 939 |
SBCS |
1172 |
1027 |
1301 |
日本英語(拡張範囲)4370UDC |
| DBCS |
1001 |
300 |
| 942 |
SBCS |
1172 |
1041 |
2300 |
日本語 PC データ - 混合 |
| DBCS |
370 |
301 |
| 5026 |
SBCS |
1172 |
290 |
1301 |
日本語カタカナ(拡張範囲)1880 UDC |
| DBCS |
370 |
300 |
| 5035 |
SBCS |
1172 |
1027 |
1301 |
日本英語(拡張範囲)1880UDC |
| DBCS |
370 |
300 |
5026と5035を比較してみると、違うのは、SBCSのCPが290か1027か、ということだけですね。SBCSも漢字も、文字コードセットは同じもので、コード化スキーマも同じです。SBCSのCPのみ違います。
また、939は、SBCSのCCSIDは5035と同じく、1027なのですが、DBCSのCCSIDが違います。文字セットが、939が1001であるのに対して、5035では、370です。漢字の文字セットが違うようです。UDC(ユーザー定義文字)が片や4370なのに、5035では1880のようです。(これって、ユーザー定義文字の数なんだろうか...?これ以上詳しいことは、分かりませんでした。)
コードページ1027について
上記したように、「CCSID5035を使う」=「コードページ1027」を使うと言うことです。このコードページ、古くからホストを担当している人には、なんだか分かりにくいものですね。
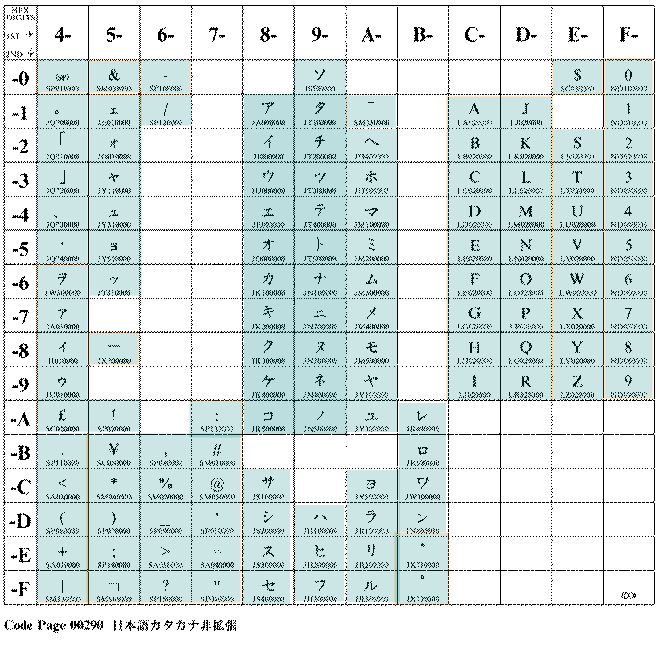
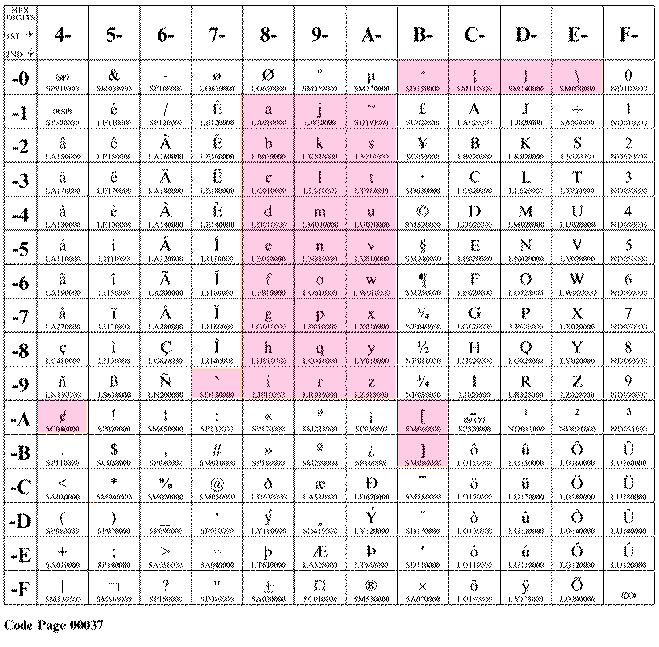
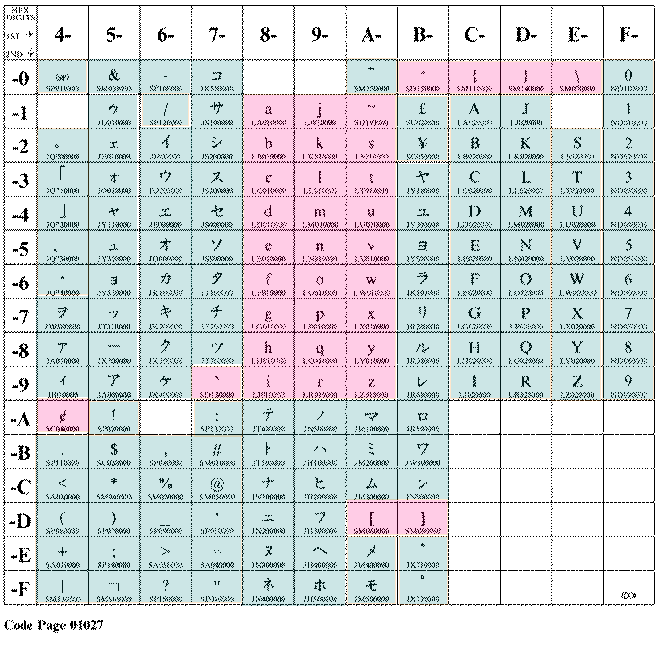
従来、日本のシステムで、EBCDICコードと呼ばれていたものは、現在はコードページは290と呼ばれています。この290(非拡張の方)の歴史はかなり古いので、変わる筈が無いと思っていましたが、インターネットの普及と、EBCDICでAS/400がそのオープンネスで、英語の小文字(たとえば、e-mailアドレスとか)を何とか、同一コードページに押し込もうとしたのが、この1027です。制定の経過は知りませんが、290のカタカナを横にずらして、37と同一の英語の小文字を、オリジナルのままの位置に入れたようです。勿論、必要が無ければ、従来の290(大昔からの日本語EBCDIC)のままでいいのですが、それでは困る場合、この1027が重要になってきます。
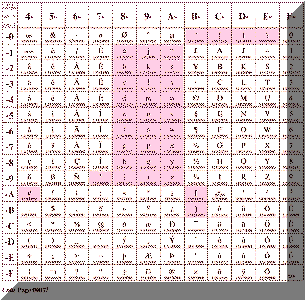
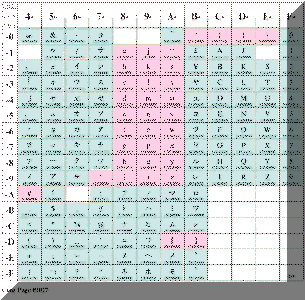
※下図で、着色した部分はコードが融合されたことを視覚的にわからせる目的です。正確にマッピングされた部分を表してはいません。
290非拡張
従来のおなじみの日本語版EBCDIC |
37
英語版EBCDIC |
 |
|
 |
|
|
1027
2つのコードページを1つのページにした新しいコードページ |
よく見れば分かりますが、290と1027ではカタカナや日本語の半角の記号の部分のコードが違っています。さらに、1027をよく見ると「ア」は、X'59'なのに、「イ」は、X'62'と飛んでいます。無理やり、ウムラウトなど、あまりなじみの無い文字にカタカナをマッピングしたみたいです。まあ、なんにしろ、1枚のコードページで、英語の小文字もカタカナも入っていますね。
文字と、それに結びつく290と1027のコード点(16進数コード)の比較表
ある文字が、各々のコードページで、どのコード点にマップされているか、ごく一部を取りだして見てみましょう。
※コード点は、各図形文字に割り当てられた 16 進値です。大文字英語や、数字は同じコード点です。特に通貨記号に注意しましょう。
| 文字 |
290
コード点
|
1027
コード点 |
| ア |
81 |
59 |
| イ |
82 |
62 |
| ウ |
83 |
63 |
| エ |
84 |
64 |
| オ |
85 |
65 |
| カ |
86 |
66 |
| キ |
87 |
67 |
| ク |
88 |
68 |
| ケ |
89 |
69 |
| コ |
8A |
70 |
| ... |
... |
... |
| \ |
5B |
B2 |
| $ |
E0 |
5B |
コード点と、それに結びついている290と1027の文字比較表
今度は切り口を変えてみましょう。あるコード点が、どの文字をあらわしているか、見てみましょう。
コード点
16進数 |
290
文字 |
1027
文字 |
| 81 |
ア |
a |
| 82 |
イ |
b |
| 83 |
ウ |
c |
| 84 |
エ |
d |
| 85 |
オ |
e |
| 86 |
カ |
f |
| 87 |
キ |
g |
| 88 |
ク |
h |
| 89 |
ケ |
i |
| 8A |
コ |
テ |
| ... |
... |
... |
| 5B |
\ |
$ |
| E0 |
$ |
\ |
| B2 |
|
\ |
※SEUでRPGのタグ名に \ など使うと、5035では、エラーになってしまいます。そのかわり、
$ はokです。まとめると、
| CCSID |
正常 |
エラー |
| 5026 |
\ |
$ |
| 5035 |
$ |
\ |
正常なのは、コード点で、x'5B'の場合ですね。SEU内部では、エラー検査が固定情報で行われているのでしょうか?したがって、タグ名やサブルーチン名に通貨記号を入れないほうがいいでしょう。
変換テーブル
変換テーブルは、QUSRSYSにありますね。WRKTBL
*ALLを実行してみると、たくさんの変換テーブルが出てきます。CCSIDはこの変換テーブルを使っています。関数でコード点の変換はいくら何でも無理でしょう。
※これらは、SBCSの変換テ-ブルみです。DBCSの変換テ-ブルは、どうやら見ることはできないようです。
テーブルの処理
オプションを入力して,実行キーを押してください。
1= 作成 3= コピー 4= 削除 5= 表示 7= 名前の変更 13= 記述の変更
OPT テーブル ライブラリー テキスト
QA3TA6G897 QUSRSYS CHRID(*N 1027) TO CHRID(1122 897) TRANSLATE TABLE
QA3TA7UA38 QUSRSYS CHRID(*N 1027) TO CHRID(1172 1041) TRANSLATE TABL
QA3TA7U290 QUSRSYS CHRID(*N 1027) TO CHRID(1172 290) TRANSLATE TABLE
QA3T697037 QUSRSYS CHRID(*N 1027) TO CHRID(697 037) TRANSLATE TABLE
QA3T697500 QUSRSYS CHRID(*N 1027) TO CHRID(697 500) TRANSLATE TABLE
QA33A93A3Q QUSRSYS CHRID(*N 1036) TO CHRID(1252 1024) TRANSLATE TABL
QA38A51850 QUSRSYS CHRID (*N 1041) TO CHRID(1106 850) TRANSLATE TABL
QA38A7UA3T QUSRSYS CHRID(*N 1041) TO CHRID(1172 1027) TRANSLATE TABL
QA38A7U290 QUSRSYS CHRID(*N 1041) TO CHRID(1172 290) TRANSLATE TABLE
QA5IA7V833 QUSRSYS CHRID(*N 1088) TO CHRID(1173 833) TRANSLATE TABLE
QA5KA7U290 QUSRSYS CHRID(*N 1090) から CHRID(1172 290)
続く ...
オプション 1, 3, 7, 13 のパラメーターまたはコマンド
===>
F3= 終了 F4=プロンプト F5= 最新表示 F9=コマンド の複写 F11= 名前のみの表示
F12= 取消し F16= 位置指定の繰返し F17= 位置指定 F24= キーの続き
|
ここで、QA3TA7U290(CP1027からCP290へ)の中身を見てみると、
変換テーブルの表示
テーブル : QA3TA7U290 ライブラリー : QUSRSYS
16 進数 16 進数 16 進数 16 進数 16 進数 16 進数
入力 出力 入力 出力 入力 出力
59 81 68 88 77 92
5A 5A 69 89 78 93
5B E0 6A 59 79 79
5C 5C 6B 6B 7A 7A
5D 5D 6C 6C 7B 7B
5E 5E 6D 6D 7C 7C
5F 5F 6E 6E 7D 7D
60 60 6F 6F 7E 7E
61 61 70 8A 7F 7F
62 82 71 8C 80 6A
63 83 72 8D 81 62
64 84 73 8E 82 63
65 85 74 8F 83 64
66 86 75 90 84 65
67 87 76 91 85 66
続く ...
F3= 終了 F12= 取消し F17= 位置指定
|
コード点の変換でカタカナの部分の変換がどうなっているか、分かりますね。
この中で、英語の小文字の、81以降が、62になっていますね。これは、290の拡張版の英語の小文字へ変換しています。困るなぁ。なんで、290が2つ(拡張と非拡張)あるんでしょう????英語の大文字にしてくれればいいのに。
※CCSIDに関係する(メッセージやセカンドレベルメッセージにCCSIDを含む)メッセージIDの一覧は、ccsidmsg.txt、です。何かの参考にしてください。
豆知識
65535の意義
CCSIDが、後からできた機能なので、その機能が無いころとの互換性保証、または、機能が無い状態をあらわすため、に作られたコードです。65535と言う数字は、多分、216
= 28×28 = 256 × 256 =
65,536
に由来するものでしょう。何も考えず、CCSIDの無いバージョンのOSから、ただバージョンアップすると、65535になります。また、未確認ですが、新規に日本で購入したマシンでは、初期値が、5026になっているようです。コードページ290をもつCCSIDが5026なので、間違いではないのですが、日本IBMとしては5035の使用を強く推薦しているようです。はやく、日本のIBM系のデファクトスタンダードのCCSIDを5035にしたいようです。(気持ちはわかるのですが...)
CPYFのFMTOPT(*MAP)で変換
*MAP が指定されていて,取出しファイル・フィールドの CCSID および受入 れファイル・フィールドの CCSID の間に正しい変換が定義されている場合 には,文字データは受入れファイル・フィールドの CCSID に変換されま す。しかし,取出しファイル・フィールドの CCSID または受入れファイ ル・フィールドの CCSID のいずれかが 65535 である場合には,文字データ は変換されません。
5026のファイルから5035へ、変換したい場合、CPYFでできますが、FMTOPTは、*NOCHKではなく、*MAPで実行しないと、変換されません。注意してください。
混合CCSID
もし、フィールドに漢字属性(DBCS属性)を含まないファイルを、作成すると、5026の環境では、CCSIDは290になり、5035ではCCSIDは1027になります。これは、CCSID5035が、混合CCSID(SBCS+DBCS)を意味しているため、DBCSを含まない場合は、1027のみのコードページ(CCSIDも1027)になるためです。まあ、SBCSのCPを5035と同じにしたいだけなら、1027でも同じです。
2000-12-31
|